RTG #4: Doom vs Animal Crossing

In this article we’ll work with the Doom vs Animal Crossing dataset. A computer vision challenge to classify images from two different subreddits.
The data
The data was taken from Reddit’s /r/Doom and /r/AnimalCrossing and the images are the best posts from those subreddits in the month of July 2020. There are 757 Animal Crossing (AC) images and 840 Doom images.
Initially, I expected some kind of similarity between the images. Having played neither Doom or Animal Crossing I thought maybe the games used a similar color palette or maybe they had characters that looked alike or some other characteristic that made it hard to differentiate between the images. Turns out there is no such thing. In fact, most of the images have little to do with how the games look.

 Samples images from the Doom x AC dataset. Top = AC, Bottom = Doom
Samples images from the Doom x AC dataset. Top = AC, Bottom = Doom
In the end, it’s all memes, and identifying where each meme belongs is hard. In some cases, you need to pretty much read what’s written, in others, you need to understand a subtle reference, and there are some that are basically impossible to tell apart.
The dataset also has some metadata about the Reddit posts, with information like the number of upvotes, date of creation, number of comments, etc. but those were ignored.
The solution
As we’re dealing with images, I opted to use a Convolutional Neural Network (CNN), and as the problem has only two possible classes (Doom image or AC image) I tried to do a logistic regression.
The normal approach to image classification is to have your network’s last layer output probabilities for each of the possible classes (in this case 2). In my approach, the network outputs a single probability. If that probability is greater than 0.5 the image is classified as a Doom image. If that doesn’t happen, it is an AC image.
To have any hope of achieving a decent score in this task without wasting all my Kaggle GPU hours, I went with some transfer learning. The architecture of choice was a Resnet50 pre-trained on ImageNet with the last layer adapted to have a single output instead of the original 1000.
Some things to consider with this approach are:
- The size of the images: The original network was trained on ImageNet, meaning that it dealt with 224x224 images. The Doom vs AC dataset has images of all kinds of sizes, with most being bigger than that. To feed the images to the network, a resizing step is required, and this resizing could distort the features enough to the point of them not being recognized by the network, as it was pre-trained with non-distorted images and learned non-distorted features
- Data augmentation: I opted to do no data augmentation. A significant number of memes in the dataset have text, and the CNN has little to no hope of extracting anything other than some shapes from the text in the image. With a modest number of training samples, distorted images, and limited GPU hours, I decided not to make the network’s job harder by flipping and cropping letters.
Implementation
Pytorch Lightning was the tool of choice to implement everything, mostly because it handles moving tensors in/out of the GPU and it provides a painless way to train using multiple GPUs, which are present in some Kaggle notebooks.
Having used TensorFlow, I was familiar with the flow_from_directory function to deal with datasets that had an image folder with subfolders for each class. I wasn’t aware, however, of the Pytorch equivalent: ImageFolder (later I found out that the real equivalent was folder_dataset.ImageFolder)
Most Pytorch examples I encountered implemented their own Datasets, so it took a while to find it, but it was really useful. If your dataset looks like this, ImageFolder is the way to go.
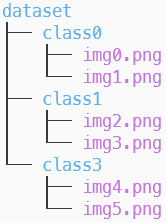
 Dataset directory structure
Dataset directory structure
For image classification, Binary Cross Entropy is the standard loss function. One thing I did not know is that Pytorch has another one called BCEWithLogitsLoss that imbues a Sigmoid layer in the BCE calculation, enabling it to work with raw logits (the unnormalized output of the neural network) instead of probabilities.
This setting is more numerically stable and allows an interesting way to calculate the accuracy, where you skip converting the network’s output to probabilities and work with the logits directly:
1
accuracy = ((logits > 0.0) == y).float().mean()
When using a sigmoid, a logit of 0 corresponds to a probability of 0.5, so instead of comparing probabilities to 0.5 it compares logits to 0.0. Then the results are put against the labels y and aggregated to form the accuracy.
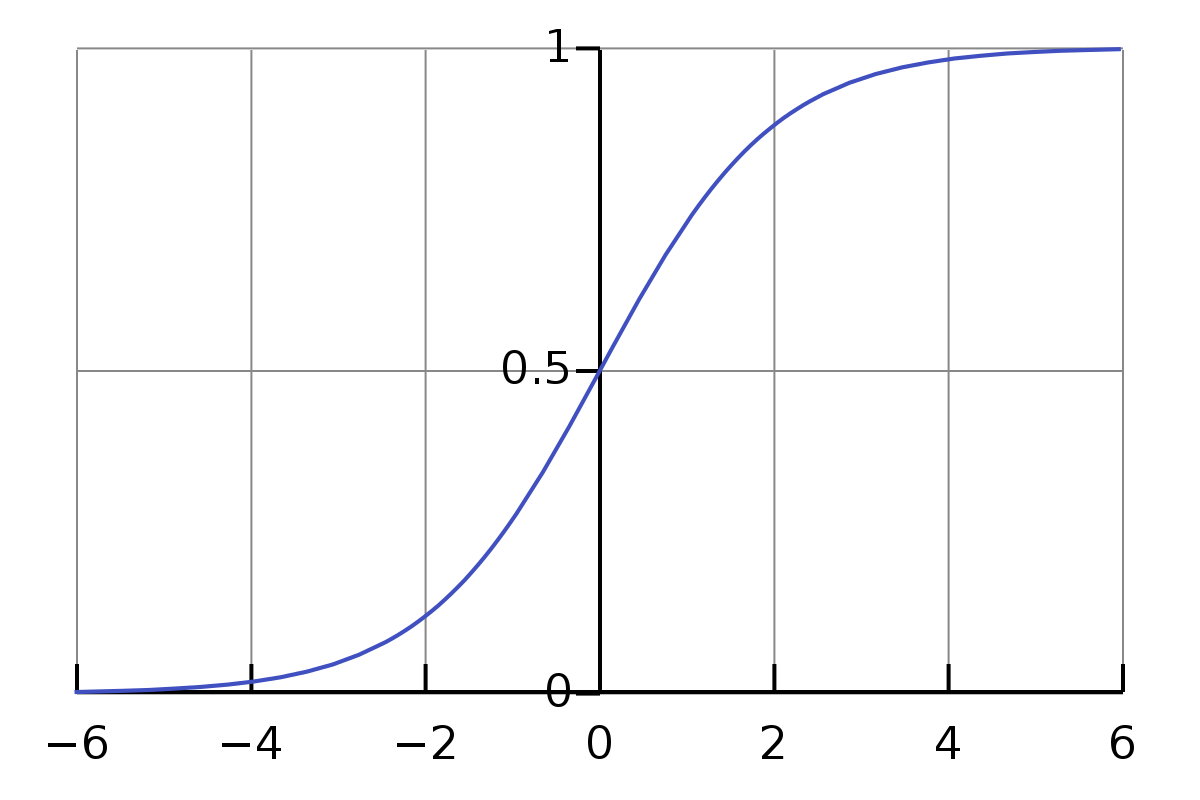
 Sigmoid function
Sigmoid function
Training
The data was divided into a 0.7/0.15/0.15 train/val/test split. Training the network wasn’t much of a hassle. One thing that worked well was lowering the learning rate as validation accuracy started to plateau.
One thing that didn’t work well was freezing the earlier layers, but this I suspect was because of distortion of the image features due to resizing. If the early layers are frozen, they can’t adapt to fit the new distorted features.
In the end, the best result I could achieve was 0.916 validation accuracy with 0.858 test accuracy. Below are some of the network’s predictions on the test data.
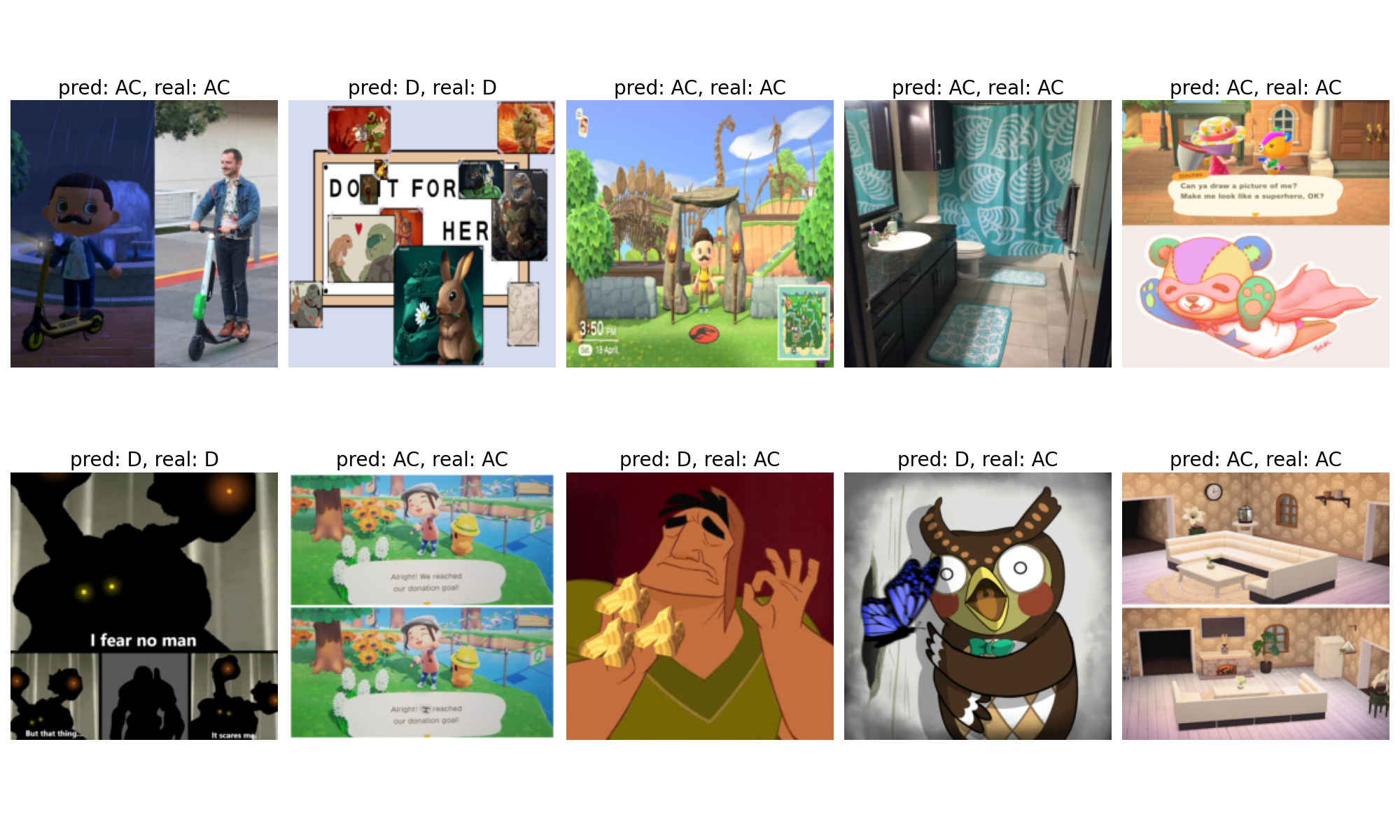
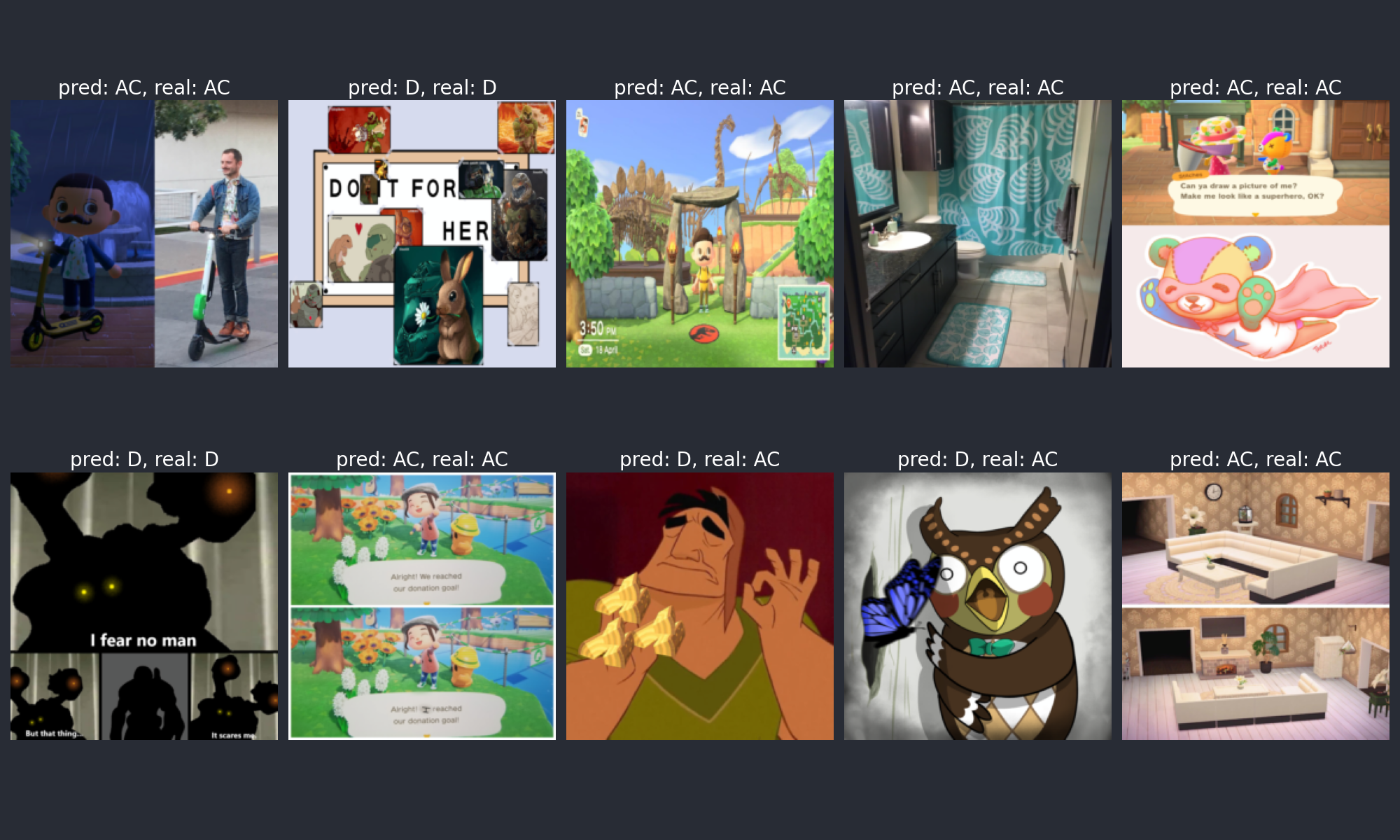 Predictions on test data
Predictions on test data
Conclusion
The model seems to work fairly well. I honestly thought that it would perform much worse at this task, but it looks like there weren’t that many ambiguous images in the dataset. The two subreddits like to reference each other a lot for some reason, so I expected a lot of the “impossible to tell apart cases”.
Looking at the predictions, the model seems to have picked up that the AC images generally have a brighter color palette, while the Doom images have a darker one. It also explains some of the mistakes: cases where no “signature element” of any of the games was present, and the color palette was different than usual.